
SAS: conjuntos de datos federados
AREAtutorial » Big Data & Analitycs » SAS: conjuntos de datos federados
Se pueden combinar varios conjuntos de datos SAS en un conjunto de datos utilizando COLOCAR declaración. El número total de casos en el conjunto de datos combinado es la suma del número de casos en los conjuntos de datos originales. El orden de observación es secuencial. Todas las observaciones del primer conjunto de datos van seguidas de todas las observaciones del segundo conjunto de datos, y así sucesivamente.
Idealmente, todos los conjuntos de datos que se fusionan tienen las mismas variables, pero si tienen un número diferente de variables, el resultado son todas las variables con valores perdidos para el conjunto de datos más pequeño.
La sintaxis básica de la instrucción SET en SAS es:
SET data-set 1 data-set 2 data-set 3.....;
A continuación se muestra la descripción de los parámetros utilizados:
conjunto de datos1, conjunto de datos2 – los nombres de los conjuntos de datos registrados uno tras otro.
Considere los datos de los empleados de una organización que están disponibles en dos conjuntos de datos diferentes, uno para el departamento de TI y otro para el departamento que no es de TI. Para obtener información completa sobre todos los empleados, combinamos ambos conjuntos de datos utilizando la declaración SET que se muestra a continuación.
DATA ITDEPT; INPUT empid name $ salary ; DATALINES; 1 Rick 623.3 3 Mike 611.5 6 Tusar 578.6 ; RUN; DATA NON_ITDEPT; INPUT empid name $ salary ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; SET ITDEPT NON_ITDEPT; RUN; PROC PRINT DATA = All_Dept; RUN;
Cuando se ejecuta el código anterior, obtenemos el siguiente resultado.
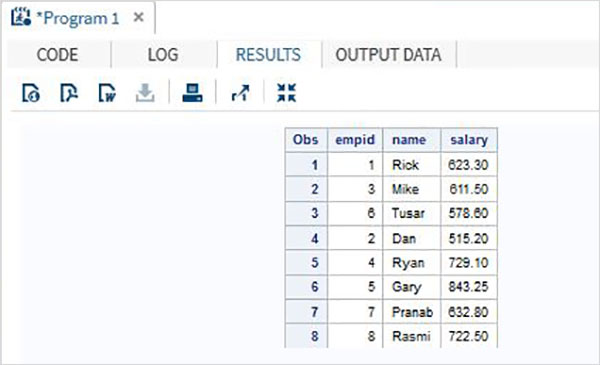
Cuando tenemos muchas variaciones en los conjuntos de datos para concatenar, el resultado de las variables puede diferir, pero el número total de casos en el conjunto de datos combinado es siempre la suma de los casos en cada conjunto de datos. A continuación, consideraremos muchos de los escenarios para esta opción.
Si uno de los conjuntos de datos originales tiene más variables que el otro, los conjuntos de datos aún se fusionan, pero el conjunto de datos más pequeño muestra esas variables como faltantes.
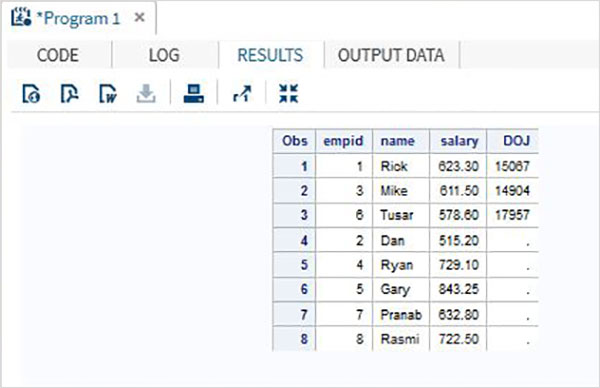
En el siguiente ejemplo, el primer conjunto de datos tiene una variable adicional denominada DOJ. Como resultado, no habrá ningún valor DOJ para el segundo conjunto de datos.
DATA ITDEPT; INPUT empid name $ salary DOJ date9. ; DATALINES; 1 Rick 623.3 02APR2001 3 Mike 611.5 21OCT2000 6 Tusar 578.6 01MAR2009 ; RUN; DATA NON_ITDEPT; INPUT empid name $ salary ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; SET ITDEPT NON_ITDEPT; RUN; PROC PRINT DATA = All_Dept; RUN;
Cuando se ejecuta el código anterior, obtenemos el siguiente resultado.
En este escenario, los conjuntos de datos tienen el mismo número de variables, pero sus nombres de variables son diferentes. En este caso, la concatenación normal producirá todas las variables en el conjunto de resultados y dará resultados faltantes para dos variables que son diferentes. Si bien no podemos cambiar el nombre de la variable en los conjuntos de datos originales, podemos usar la función RENAME en el conjunto de datos fusionado que estamos creando. Esto dará el mismo resultado que la concatenación normal, pero por supuesto con un nuevo nombre de variable en lugar de los dos nombres de variable diferentes presentes en el conjunto de datos original.
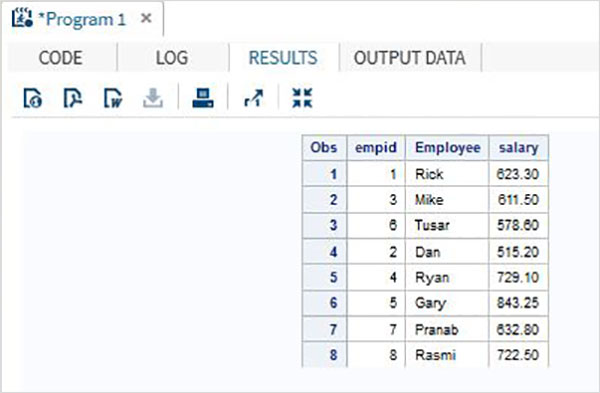
En el siguiente ejemplo, el conjunto de datos ITDEPT tiene un nombre de variable esmalte mientras que el conjunto de datos NON_ITDEPT tiene un nombre de variable empname. Pero ambas variables representan el mismo tipo (carácter). Aplicamos REBAUTIZAR en una instrucción SET como se muestra a continuación.
DATA ITDEPT; INPUT empid ename $ salary ; DATALINES; 1 Rick 623.3 3 Mike 611.5 6 Tusar 578.6 ; RUN; DATA NON_ITDEPT; INPUT empid empname $ salary ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; SET ITDEPT(RENAME =(ename = Employee) ) NON_ITDEPT(RENAME =(empname = Employee) ); RUN; PROC PRINT DATA = All_Dept; RUN;
Cuando se ejecuta el código anterior, obtenemos el siguiente resultado.
Si la longitud de la variable en los dos conjuntos de datos es diferente a la del conjunto de datos combinado, tendrá valores en los que algunos datos se truncan para una variable con una longitud más corta. Esto sucede si el primer conjunto de datos es más corto. Para resolver este problema, aplicamos una gran longitud a ambos conjuntos de datos como se muestra a continuación.
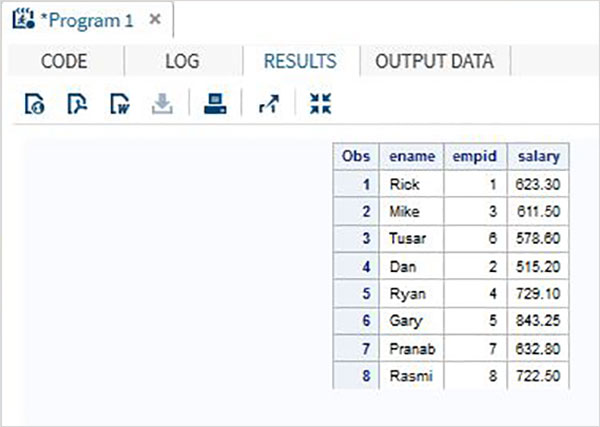
En el siguiente ejemplo, la variable esmalte tiene una longitud de 5 en el primer conjunto de datos y 7 en el segundo. Al fusionar, usamos el operador LENGTH en el conjunto de datos combinado para establecer la longitud del esmalte en 7.
DATA ITDEPT; INPUT empid 1-2 ename $ 3-7 salary 8-14 ; DATALINES; 1 Rick 623.3 3 Mike 611.5 6 Tusar 578.6 ; RUN; DATA NON_ITDEPT; INPUT empid 1-2 ename $ 3-9 salary 10-16 ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; LENGTH ename $ 7 ; SET ITDEPT NON_ITDEPT ; RUN; PROC PRINT DATA = All_Dept; RUN;
Cuando se ejecuta el código anterior, obtenemos el siguiente resultado.
🚫