
SAS: clasificación de conjuntos de datos
AREAtutorial » Big Data & Analitycs » SAS: clasificación de conjuntos de datos
Los conjuntos de datos SAS se pueden ordenar por cualquiera de las variables que contienen. Esto ayuda tanto cuando se analizan los datos como cuando se realizan otras opciones, como la fusión, etc. La clasificación puede ocurrir en cualquier variable individual, así como en varias variables. El procedimiento SAS utilizado para realizar la clasificación en un conjunto de datos SAS se llama PROCEDIMIENTO DE CLASIFICACIÓN… Después de ordenar, el resultado se guarda en el nuevo conjunto de datos y el conjunto de datos original permanece sin cambios.
La sintaxis básica para una operación de clasificación en un conjunto de datos en SAS es:
PROC SORT DATA = original dataset OUT = Sorted dataset; BY variable name;
A continuación se muestra la descripción de los parámetros utilizados:
nombre de la variable es el nombre de la columna por la que ordenar.
Conjunto de datos original este es el nombre del conjunto de datos que se ordenará.
Conjunto de datos ordenados este es el nombre del conjunto de datos después de ordenarlo.
Echemos un vistazo al siguiente conjunto de datos SAS que contiene información sobre las personas de una organización. Podemos ordenar el conjunto de datos por salario usando el siguiente código.
DATA Employee; INPUT empid name $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; RUN; PROC SORT DATA = Employee OUT = Sorted_sal ; BY salary; RUN ; PROC PRINT DATA = Sorted_sal; RUN ;
Cuando se ejecuta el código anterior, obtenemos el siguiente resultado.
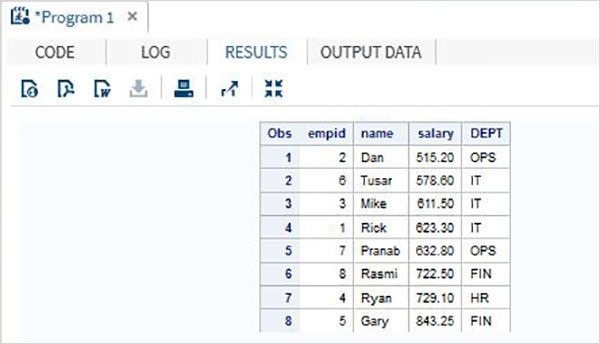
La opción de clasificación predeterminada está en orden ascendente, lo que significa que los casos se ordenan según el valor de menor a mayor de la variable ordenada. Pero también podemos querer que la clasificación se haga en orden ascendente.
En el siguiente código, la ordenación inversa se logra utilizando el operador DESCENDENTE.
DATA Employee; INPUT empid name $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; RUN; PROC SORT DATA = Employee OUT = Sorted_sal_reverse ; BY DESCENDING salary; RUN ; PROC PRINT DATA = Sorted_sal_reverse; RUN ;
Cuando se ejecuta el código anterior, obtenemos el siguiente resultado.
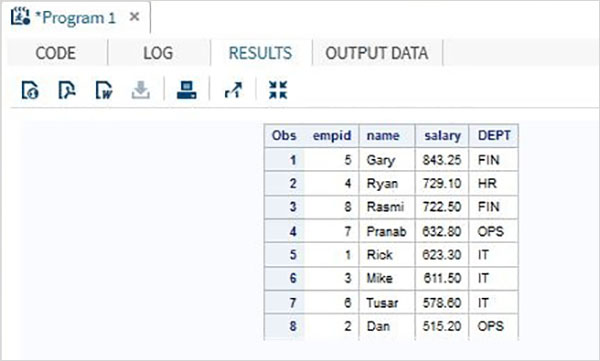
La ordenación se puede aplicar a múltiples variables usándolas con la cláusula BY. Las variables se ordenan con prioridad de izquierda a derecha.
En el siguiente código, el conjunto de datos se ordena primero por el nombre de departamento de la variable y luego por el nombre de la variable de salario.
DATA Employee; INPUT empid name $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; RUN; PROC SORT DATA = Employee OUT = Sorted_dept_sal ; BY salary DEPT; RUN ; PROC PRINT DATA = Sorted_dept_sal; RUN ;
Cuando se ejecuta el código anterior, obtenemos el siguiente resultado.
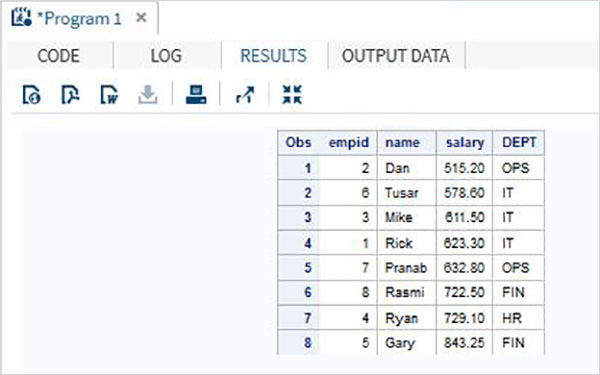
🚫