
SAS: lectura de datos sin procesar
AREAtutorial » Big Data & Analitycs » SAS: lectura de datos sin procesar
SAS puede leer datos de una variedad de fuentes, incluidos muchos formatos de archivo. Los formatos de archivo utilizados en el entorno SAS se describen a continuación.
Estos son archivos que contienen datos en formato de texto. Los datos generalmente están delimitados por un espacio, pero también puede haber diferentes tipos de delimitadores que SAS puede manejar. Considere un archivo ASCII que contiene datos de empleados. Leemos este archivo usando En archivo la declaración está disponible en SAS.
En el siguiente ejemplo, estamos leyendo un archivo de datos llamado emp_data.txt del entorno local.
data TEMP; infile '/folders/myfolders/sasuser.v94/AreaTutorial/emp_data.txt'; input empID empName $ Salary Dept $ DOJ date9. ; format DOJ date9.; run; PROC PRINT DATA = TEMP; RUN;
Cuando se ejecuta el código anterior, obtenemos el siguiente resultado.
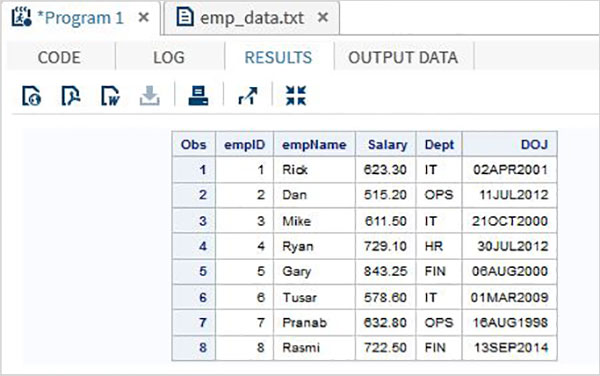
Estos son archivos de datos donde los valores de las columnas están separados por un carácter separador como una coma o una barra vertical, etc. En este caso, usamos dlm opción en en archivo declaración.
En el siguiente ejemplo, estamos leyendo un archivo de datos llamado emp.csv del entorno local.
data TEMP; infile '/folders/myfolders/sasuser.v94/AreaTutorial/emp.csv' dlm=","; input empID empName $ Salary Dept $ DOJ date9. ; format DOJ date9.; run; PROC PRINT DATA = TEMP; RUN;
Cuando se ejecuta el código anterior, obtenemos el siguiente resultado.
SAS puede leer directamente el archivo de Excel utilizando el importador. Como puede ver en el capítulo Conjuntos de datos de SAS, puede manejar una amplia variedad de tipos de archivos, incluido MS Excel. Suponiendo que el archivo emp.xls esté disponible localmente en el entorno SAS.
FILENAME REFFILE "/folders/myfolders/AreaTutorial/emp.xls" TERMSTR = CR; PROC IMPORT DATAFILE = REFFILE DBMS = XLS OUT = WORK.IMPORT; GETNAMES = YES; RUN; PROC PRINT DATA = WORK.IMPORT RUN;
El código anterior lee datos de un archivo de Excel y da el mismo resultado que los dos tipos de archivos anteriores.
En estos archivos, los datos se presentan en formato jerárquico. Hay una entrada de título para esta observación, debajo de la cual se mencionan muchas entradas detalladas. El número de registros detallados puede variar de una observación a otra. A continuación se muestra una ilustración de un archivo jerárquico.
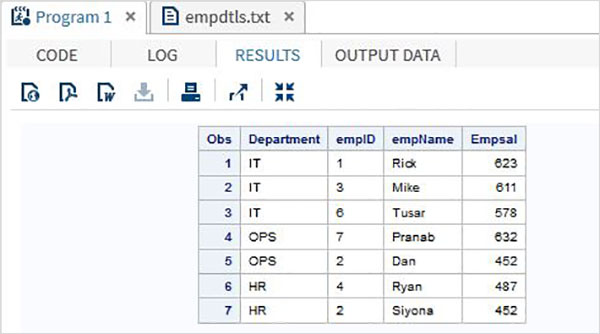
El archivo a continuación enumera los detalles de cada empleado en cada departamento. El primer registro es el registro de título que menciona el departamento y el siguiente registro, varios registros que comienzan con DTLS, es el registro de detalle.
DEPT:IT DTLS:1:Rick:623 DTLS:3:Mike:611 DTLS:6:Tusar:578 DEPT:OPS DTLS:7:Pranab:632 DTLS:2:Dan:452 DEPT:HR DTLS:4:Ryan:487 DTLS:2:Siyona:452
Para leer un archivo jerárquico, usamos el código a continuación donde identificamos el registro de encabezado con una cláusula IF y usamos un bucle do para procesar el registro de detalles.
data employees(drop = Type);
length Type $ 3 Department
empID $ 3 empName $ 10 Empsal 3 ;
retain Department;
infile
'/folders/myfolders/AreaTutorial/empdtls.txt' dlm = ':';
input Type $ @;
if Type="DEP" then
input Department $;
else do;
input empID empName $ Empsal ;
output;
end;
run;
PROC PRINT DATA = employees;
RUN;
Cuando se ejecuta el código anterior, obtenemos el siguiente resultado.
🚫