
MapReduce – Introducción
AREAtutorial » Big Data & Analitycs » MapReduce – Introducción
MapReduce es un modelo de programación para escribir aplicaciones que pueden procesar big data en paralelo a través de múltiples nodos. MapReduce proporciona capacidades analíticas para analizar cantidades masivas de datos complejos.
Big data es una colección de grandes conjuntos de datos que no se pueden procesar con tecnologías informáticas tradicionales. Por ejemplo, la cantidad de datos que Facebook o Youtube necesitan recopilar y procesar a diario puede pertenecer a la categoría de big data. Sin embargo, el big data no se trata solo de escala y volumen, sino que también incluye una o más de las siguientes dimensiones: velocidad, variedad, volumen y complejidad.
Los sistemas corporativos tradicionales suelen tener un servidor centralizado para almacenar y procesar datos. La siguiente figura muestra esquemáticamente un sistema corporativo tradicional. El modelo tradicional ciertamente no es adecuado para manejar grandes volúmenes de datos escalables y no puede ser acomodado por servidores de bases de datos estándar. Además, el sistema centralizado crea demasiados cuellos de botella al procesar varios archivos al mismo tiempo.
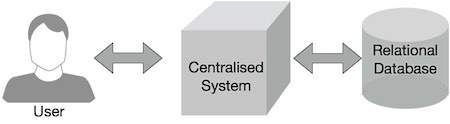
Google resolvió este problema de cuello de botella con el algoritmo MapReduce. MapReduce divide una tarea en partes pequeñas y las asigna a varias computadoras. Los resultados se recopilan posteriormente en un solo lugar y se combinan para formar un conjunto de datos de resultados.
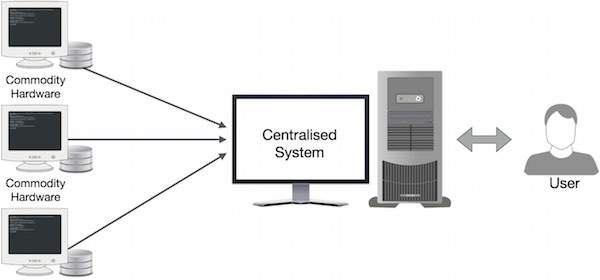
El algoritmo MapReduce contiene dos tareas importantes, a saber, Map y Reduce.
La tarea Mapa toma un conjunto de datos y lo transforma en otro conjunto de datos, donde los elementos individuales se dividen en tuplas (pares clave-valor).
La tarea Reducir toma la salida de un mapa como entrada y combina estas tuplas de datos (pares clave-valor) en un conjunto más pequeño de tuplas.
La tarea de poda siempre se realiza después de que se establece el mapa.
Echemos ahora un vistazo de cerca a cada una de las etapas e intentemos comprender su significado.
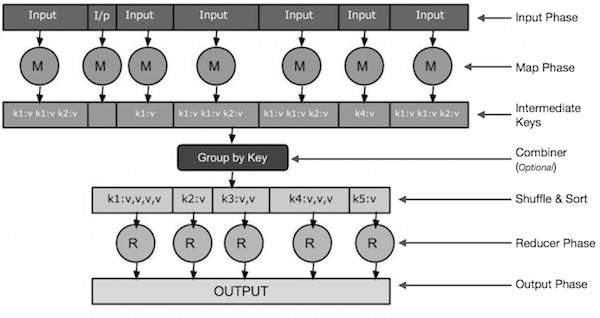
Fase de entrada “Aquí tenemos un lector de registros que traduce cada registro en el archivo de entrada y envía los datos analizados al asignador como pares clave-valor.
mapa – Map es una función definida por el usuario que toma una serie de pares clave-valor y procesa cada uno para crear cero o más pares clave-valor.
Teclas intermedias – Estos pares clave-valor generados por el transformador se conocen como claves intermedias.
Combinador – Un combinador es un tipo de reductor local que agrupa datos similares de una fase del mapa en conjuntos identificables. Toma claves intermedias de un transformador como entrada y aplica código definido por el usuario para agregar valores en un área pequeña de un solo transformador. No es parte del algoritmo principal de MapReduce; no es obligatorio.
Revuelva y clasifique – La tarea «Reductor» comienza con la etapa «Mezclar y ordenar». Descarga los pares clave-valor agrupados en la computadora local que ejecuta Reducer. Los pares clave-valor individuales se ordenan por clave en una lista de datos más grande. La hoja de datos agrupa claves equivalentes juntas para que sus valores se puedan duplicar fácilmente en la tarea Reducer.
Reductor – El reductor toma los datos del par clave-valor agrupados como entrada y ejecuta la función reductor para cada uno. Aquí, los datos se pueden agregar, filtrar y combinar de diversas formas, y esto requiere una amplia gama de procesamiento. Al final de la ejecución, el último paso genera cero o más pares clave-valor.
Fase de salida – En la fase de salida, tenemos un formateador de salida que traduce los pares clave-valor finales de la función Reducer y los escribe en un archivo usando el escritor.
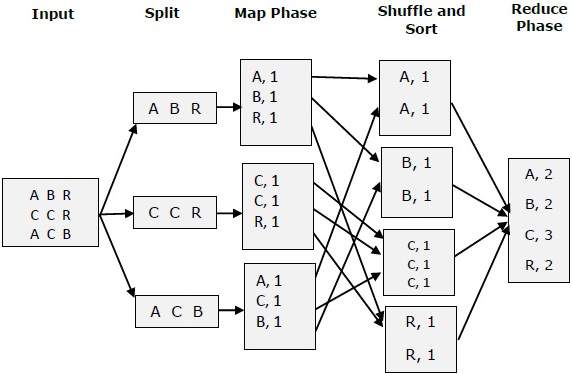
Intentemos comprender dos tareas de Map & f Reduce con la ayuda de un pequeño diagrama:
Tomemos un ejemplo de la vida real para comprender las capacidades de MapReduce. Twitter recibe alrededor de 500 millones de tweets por día, lo que equivale a casi 3,000 tweets por segundo. La siguiente figura muestra cómo Tweeter administra sus tweets usando MapReduce.
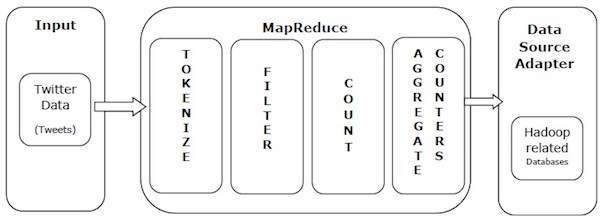
Como se muestra en la figura, el algoritmo MapReduce hace lo siguiente:
Tokenizar – Tokeniza tweets en mapas de token y los escribe como pares clave-valor.
Filtrar – Filtra palabras no deseadas de mapas de tokens y escribe mapas filtrados como pares clave-valor.
Pensar – Crea un contador de fichas por palabra.
Metros agregados – Prepara una colección de valores de contador idénticos en pequeñas unidades manejables.
🚫