
MapReduce – Combinadores
AREAtutorial » Big Data & Analitycs » MapReduce – Combinadores
Operador de combinación, también conocido como semi-reductor, es una clase opcional que toma la entrada de la clase Map y luego pasa los pares clave-valor de salida a la clase Reducer.
La función principal del Combiner es resumir los registros de salida de la tarjeta con la misma clave. La salida (colección clave / valor) del combinador se enviará a través de la red a la tarea Reducer real como entrada.
La clase Combiner se usa entre la clase Map y la clase Reduce para reducir la cantidad de transferencia de datos entre Map y Reduce. Normalmente, la salida de la tarea de mapa es grande y la cantidad de datos que se pasan a la tarea de poda es grande.
El siguiente diagrama de tareas de MapReduce muestra la FASE COMBINADOR.
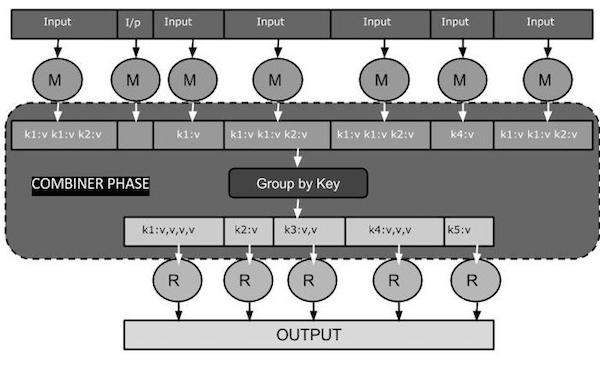
Aquí hay un breve resumen de cómo funciona MapReduce Combiner:
El combinador no tiene una interfaz predefinida y debe implementar el método reduce () de la interfaz Reducer.
El combinador funciona con cada llave de extracción de tarjetas. Debe tener los mismos tipos de valor y clave de salida que la clase Reducer.
El combinador puede producir información resumida a partir de un gran conjunto de datos, ya que reemplaza la salida del mapa original.
Aunque el Combinador es opcional, ayuda a dividir los datos en varios grupos para la fase de poda, lo que facilita el procesamiento.
El siguiente ejemplo proporciona una comprensión teórica de los combinadores. Supongamos que tenemos el siguiente archivo de texto de entrada llamado input.txt para MapReduce.
What do you mean by Object What do you know about Java What is Java Virtual Machine How Java enabled High Performance
Los pasos importantes en un programa MapReduce con Combiner se analizan a continuación.
Esta es la primera fase de MapReduce, en la que el lector de registros lee cada línea del archivo de texto de entrada como texto y genera la salida como pares clave-valor.
aporte – Texto línea a línea del archivo de entrada.
Salida – Formas pares clave-valor. A continuación se muestra un conjunto de pares clave-valor esperados.
<1, What do you mean by Object> <2, What do you know about Java> <3, What is Java Virtual Machine> <4, How Java enabled High Performance>
El paso de mapeo ingresa datos del lector de registros, los procesa y los genera como otro conjunto de pares clave-valor.
aporte – El siguiente par clave / valor es la entrada recibida del lector de registros.
<1, What do you mean by Object> <2, What do you know about Java> <3, What is Java Virtual Machine> <4, How Java enabled High Performance>
La fase de coincidencia lee cada par clave / valor, quita cada palabra del valor usando un StringTokenizer, trata cada palabra como una clave y trata esa palabra como un valor. El siguiente fragmento de código muestra la función Mapper y la clase Mapper.
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
Salida – El resultado esperado es el siguiente –
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1> <What,1> <do,1> <you,1> <know,1> <about,1> <Java,1> <What,1> <is,1> <Java,1> <Virtual,1> <Machine,1> <How,1> <Java,1> <enabled,1> <High,1> <Performance,1>
En la etapa de concatenación, cada par clave-valor de la etapa de coincidencia se procesa y se muestra como colección de clave-valor parejas.
aporte – El siguiente par clave-valor es la entrada del paso de coincidencia.
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1> <What,1> <do,1> <you,1> <know,1> <about,1> <Java,1> <What,1> <is,1> <Java,1> <Virtual,1> <Machine,1> <How,1> <Java,1> <enabled,1> <High,1> <Performance,1>
La fase de concatenación lee cada par clave-valor, concatena palabras comunes como clave y valores como colección. Por lo general, el código y el funcionamiento del Combiner son similares al programa Reducer. A continuación se muestra un fragmento de código para declarar las clases Mapper, Combiner y Reducer.
job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class);
Salida – El resultado esperado es el siguiente –
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1> <know,1> <about,1> <Java,1,1,1> <is,1> <Virtual,1> <Machine,1> <How,1> <enabled,1> <High,1> <Performance,1>
La fase reductora toma cada par clave-valor de la colección de la fase de fusión, lo procesa y pasa la salida como pares clave-valor. Tenga en cuenta que la funcionalidad Combiner es la misma que Reducer.
aporte – El siguiente par clave-valor es la entrada del paso de combinación.
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1> <know,1> <about,1> <Java,1,1,1> <is,1> <Virtual,1> <Machine,1> <How,1> <enabled,1> <High,1> <Performance,1>
La fase de reducción lee cada par clave-valor. A continuación se muestra el fragmento de código de Combiner.
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
Salida – El resultado esperado de la fase reductora es el siguiente:
<What,3> <do,2> <you,2> <mean,1> <by,1> <Object,1> <know,1> <about,1> <Java,3> <is,1> <Virtual,1> <Machine,1> <How,1> <enabled,1> <High,1> <Performance,1>
Esta es la última etapa de MapReduce, donde el escritor escribe cada par clave-valor de la etapa reductor y envía el resultado como texto.
aporte – Cada par clave-valor de la etapa Reducer junto con el formato de salida.
Salida – Le brinda pares clave-valor en formato de texto. El resultado esperado se muestra a continuación.
What 3 do 2 you 2 mean 1 by 1 Object 1 know 1 about 1 Java 3 is 1 Virtual 1 Machine 1 How 1 enabled 1 High 1 Performance 1
El siguiente bloque de código cuenta el número de palabras del programa.
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Guarde el programa anterior como WordCount.java… La compilación y ejecución del programa se muestra a continuación.
Digamos que estamos en el directorio de inicio del usuario de Hadoop (por ejemplo, / home / hadoop).
Siga las instrucciones a continuación para compilar y ejecutar el programa anterior.
Paso 1 – Utilice el siguiente comando para crear un directorio para almacenar clases Java compiladas.
$ mkdir units
Paso 2 – Descargue Hadoop-core-1.2.1.jar que se utiliza para compilar y ejecutar el programa MapReduce. Puede descargar el tarro desde mvnrepository.com…
Supongamos que la carpeta descargada es / home / hadoop /.
Paso 3 – Utilice los siguientes comandos para compilar WordCount.java programa y crea un frasco para el programa.
$ javac -classpath hadoop-core-1.2.1.jar -d units WordCount.java $ jar -cvf units.jar -C units/ .
Paso 4 – Utilice el siguiente comando para crear un directorio de entrada en HDFS.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dir
Paso 5 – Utilice el siguiente comando para copiar un archivo de entrada llamado input.txt en el directorio de entrada de HDFS.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/input.txt input_dir
PASO 6 – Utilice el siguiente comando para verificar archivos en el directorio de entrada.
$HADOOP_HOME/bin/hadoop fs -ls input_dir/
Paso 7. – Utilice el siguiente comando para iniciar la aplicación de conteo de palabras tomando archivos de entrada del directorio de entrada.
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dir
Espere un momento hasta que el archivo comience a ejecutarse. Una vez ejecutada, la salida contiene múltiples particiones de entrada, tareas de mapa y tareas de reducción.
Paso 8 – Utilice el siguiente comando para verificar los archivos resultantes en la carpeta de salida.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/
Paso 9 – Utilice el siguiente comando para ver la salida en Parte 00000 expediente. Este archivo es generado por HDFS.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000
A continuación se muestra la salida generada por MapReduce.
What 3 do 2 you 2 mean 1 by 1 Object 1 know 1 about 1 Java 3 is 1 Virtual 1 Machine 1 How 1 enabled 1 High 1 Performance 1
🚫