
Mahout – agrupación
AREAtutorial » Big Data & Analitycs » Mahout – agrupación
La agrupación en clústeres es un procedimiento para organizar los elementos o elementos de una colección determinada en grupos según la similitud entre los elementos. Por ejemplo, las aplicaciones relacionadas con la publicación de noticias de Internet agrupan sus artículos de noticias mediante la agrupación en clústeres.
La agrupación en clústeres se utiliza ampliamente en muchas aplicaciones, como la investigación de mercado, el reconocimiento de patrones, el análisis de datos y el procesamiento de imágenes.
La agrupación puede ayudar a los especialistas en marketing a descubrir grupos específicos dentro de su base de clientes. Y pueden caracterizar a sus grupos de clientes en función de los patrones de compra.
En biología, se puede utilizar para derivar taxonomía de plantas y animales, clasificar genes con una funcionalidad similar y obtener información sobre las estructuras inherentes a las poblaciones.
La agrupación ayuda a identificar áreas de uso similar de la tierra en la base de datos de observación de la Tierra.
La agrupación en clústeres también ayuda a clasificar documentos en Internet para el descubrimiento de información.
La agrupación en clústeres se utiliza en aplicaciones de detección de valores atípicos, como la detección de fraudes con tarjetas de crédito.
Como función de minería de datos, el análisis de conglomerados sirve como una herramienta para comprender la distribución de datos para observar las características de cada conglomerado.
Con Mahout, podemos agrupar un conjunto de datos determinado. Se requieren los siguientes pasos:
Algoritmo Debe elegir un algoritmo de agrupación en clúster adecuado para agrupar a los miembros del clúster.
Similitud y disimilitud Debe tener una regla para verificar la similitud entre los elementos recién descubiertos y los elementos en grupos.
Condición de parada Se requiere una condición de parada para definir un punto en el que no se requiere la agrupación en clústeres.
Para agrupar datos, necesita:
Inicie el servidor Hadoop. Cree los directorios necesarios para almacenar archivos en el sistema de archivos de Hadoop. (Cree directorios para el archivo de entrada, el archivo de secuencia y la salida agrupada en caso de exceso).
Copie el archivo de entrada al sistema de archivos Hadoop desde el sistema de archivos Unix.
Prepare un archivo de secuencia a partir de la entrada.
Ejecute cualquiera de los algoritmos de agrupación disponibles.
Obtenga datos del clúster.
Mahout funciona con Hadoop, así que asegúrese de que el servidor Hadoop esté en funcionamiento.
$ cd HADOOP_HOME/bin $ start-all.sh
Cree directorios en el sistema de archivos de Hadoop para almacenar el archivo de entrada, los archivos de secuencia y los datos agrupados con el siguiente comando:
$ hadoop fs -p mkdir /mahout_data $ hadoop fs -p mkdir /clustered_data $ hadoop fs -p mkdir /mahout_seq
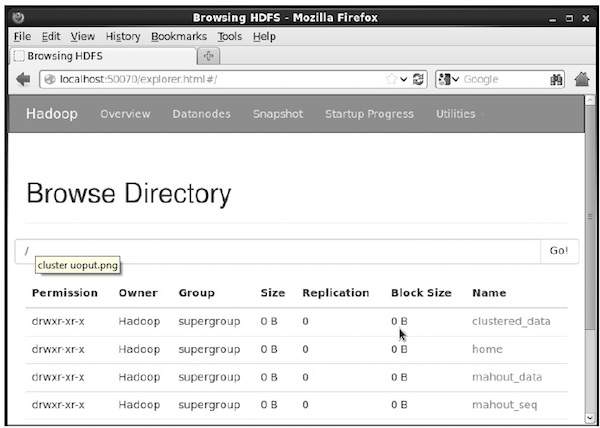
Puede verificar si el directorio se ha creado utilizando la interfaz web de hadoop en la siguiente URL: http: // localhost: 50070 /
Esto le da la salida como se muestra a continuación:
Ahora copie el archivo de datos de entrada del sistema de archivos de Linux al directorio mahout_data del sistema de archivos de Hadoop como se muestra a continuación. Suponga que su archivo de entrada es mydata.txt y está ubicado en el directorio / home / Hadoop / data /.
$ hadoop fs -put /home/Hadoop/data/mydata.txt /mahout_data/
Mahout le proporciona una utilidad para convertir un archivo de entrada dado a un formato de archivo de secuencia. Esta utilidad requiere dos parámetros.
A continuación se muestra la pista para el mahout. seqdirectory utilidad.
Paso 1: Cambie a su directorio de inicio de Mahout. Puede obtener ayuda para usar la utilidad como se muestra a continuación:
[Hadoop@localhost bin]$ ./mahout seqdirectory --help Job-Specific Options: --input (-i) input Path to job input directory. --output (-o) output The directory pathname for output. --overwrite (-ow) If present, overwrite the output directory
Genere un archivo de secuencia usando la utilidad usando la siguiente sintaxis:
mahout seqdirectory -i <input file path> -o <output directory>
Ejemplo
mahout seqdirectory -i hdfs://localhost:9000/mahout_seq/ -o hdfs://localhost:9000/clustered_data/
Mahout admite dos algoritmos principales de agrupación en clústeres, a saber:
Canopy Clustering es una técnica simple y rápida utilizada por Mahout para clustering. Los objetos se tratarán como puntos en un espacio simple. Esta técnica se utiliza a menudo como un paso inicial en otras técnicas de agrupación, como la agrupación de k-medias. Puede iniciar un trabajo de Canopy con la siguiente sintaxis:
mahout canopy -i <input vectors directory> -o <output directory> -t1 <threshold value 1> -t2 <threshold value 2>
Canopy requiere un directorio de archivos de entrada con un archivo de secuencia y un directorio de salida donde se almacenarán los datos agrupados.
Ejemplo
mahout canopy -i hdfs://localhost:9000/mahout_seq/mydata.seq -o hdfs://localhost:9000/clustered_data -t1 20 -t2 30
Obtendrá los datos del clúster generados en el directorio de salida especificado.
La agrupación en clústeres de K-medias es un algoritmo de agrupación importante. El algoritmo de agrupación de k en k-medias representa el número de agrupaciones en las que se deben dividir los datos. Por ejemplo, el valor k especificado para este algoritmo se elige como 3, el algoritmo dividirá los datos en 3 grupos.
Cada objeto se representará como un vector en el espacio. Inicialmente, k puntos serán seleccionados aleatoriamente por el algoritmo y procesados como centros, cada objeto más cercano a cada centro será agrupado. Existen varios algoritmos para medir la distancia y el usuario debe seleccionar el deseado.
Creando archivos vectoriales
A diferencia del algoritmo Canopy, el algoritmo k-means requiere archivos vectoriales como entrada, por lo que debe crear archivos vectoriales.
Para crear archivos vectoriales a partir del formato de archivo de secuencia, Mahout proporciona
seq2parse utilidad.
A continuación se muestran algunas de las opciones seq2parse utilidad. Cree archivos vectoriales usando estas opciones.
$MAHOUT_HOME/bin/mahout seq2sparse --analyzerName (-a) analyzerName The class name of the analyzer --chunkSize (-chunk) chunkSize The chunkSize in MegaBytes. --output (-o) output The directory pathname for o/p --input (-i) input Path to job input directory.
Después de crear los vectores, vaya al algoritmo k-means. La sintaxis para ejecutar el trabajo k-means es la siguiente:
mahout kmeans -i <input vectors directory> -c <input clusters directory> -o <output working directory> -dm <Distance Measure technique> -x <maximum number of iterations> -k <number of initial clusters>
La especificación de la agrupación de K-medias requiere un catálogo de vectores de entrada, un catálogo de agrupaciones de salida, una medida de distancia, el número máximo de iteraciones a realizar y un valor entero que representa la cantidad de agrupaciones en las que se debe dividir la entrada.
🚫