
Hadoop: descripción general de HDFS
AREAtutorial » Big Data & Analitycs » Hadoop: descripción general de HDFS
El sistema de archivos Hadoop se desarrolló utilizando un sistema de archivos distribuido. Funciona con hardware estándar. A diferencia de otros sistemas distribuidos, HDFS es muy resistente y está diseñado con hardware económico.
HDFS contiene una gran cantidad de datos y es más fácil de acceder. Para almacenar esta enorme cantidad de datos, los archivos se almacenan en varias máquinas. Estos archivos se almacenan de forma redundante para salvar al sistema de una posible pérdida de datos en caso de fallo. HDFS también hace que las aplicaciones estén disponibles para procesamiento paralelo.
A continuación se muestra la arquitectura del sistema de archivos Hadoop.
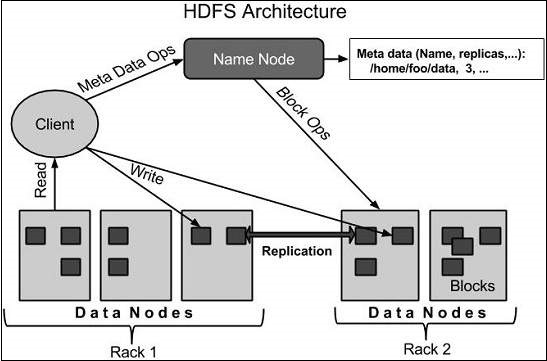
HDFS sigue una arquitectura maestro-esclavo y tiene los siguientes elementos.
Namenode es un hardware común que contiene el sistema operativo GNU / Linux y el software namenode. Es un software que se puede ejecutar en hardware común. Un sistema de nodo de nombre actúa como servidor maestro y realiza las siguientes tareas:
Administra el espacio de nombres del sistema de archivos.
Regula el acceso de los clientes a los archivos.
También realiza operaciones del sistema de archivos como cambiar el nombre, cerrar y abrir archivos y directorios.
Un nodo de datos es un hardware común con el sistema operativo GNU / Linux y el software del nodo de datos. Habrá un nodo de datos para cada nodo (equipo / sistema comercial) en el clúster. Estos nodos gestionan el almacenamiento de datos en su sistema.
Los nodos de datos realizan operaciones de lectura / escritura en sistemas de archivos a petición del cliente.
También realizan operaciones como crear, eliminar y replicar bloques de acuerdo con las instrucciones de namenode.
Normalmente, los datos del usuario se almacenan en archivos HDFS. El archivo en el sistema de archivos se dividirá en uno o más segmentos y / o se almacenará en nodos de datos separados. Estos segmentos del archivo se denominan bloques. En otras palabras, la cantidad mínima de datos que HDFS puede leer o escribir se denomina bloque. El tamaño de bloque predeterminado es 64 MB, pero puede aumentarlo si necesita cambiar la configuración de HDFS.
Solución de problemas – Dado que HDFS incluye una gran cantidad de equipos estándar, las fallas de los componentes son frecuentes. Por lo tanto, HDFS debe tener mecanismos para la detección y recuperación de fallas rápida y automática.
Grandes conjuntos de datos – HDFS debe tener cientos de nodos por clúster para administrar aplicaciones que tienen grandes conjuntos de datos.
Hardware en datos – La tarea solicitada se puede realizar de manera eficiente cuando el cálculo se realiza junto con los datos. Esto reduce el tráfico de la red y aumenta el rendimiento, especialmente cuando se trata de grandes conjuntos de datos.
🚫