
Big Data Analytics: cuadros y gráficos
AREAtutorial » Big Data & Analitycs » Big Data Analytics: cuadros y gráficos
El primer enfoque para el análisis de datos es el análisis visual. El objetivo suele ser encontrar relaciones entre variables y descripciones de variables unidimensionales. Podemos categorizar estas estrategias como:
Unidimensional término estadístico. En la práctica, esto significa que queremos analizar la variable independientemente del resto de los datos. Plotlys para hacer esto de manera efectiva:
Los diagramas de caja se utilizan comúnmente para comparar distribuciones. Esta es una excelente manera de verificar visualmente si existen diferencias entre las distribuciones. Podemos ver si hay diferencia en el precio de los diamantes de diferentes cortes.
# We will be using the ggplot2 library for plotting
library(ggplot2)
data("diamonds")
# We will be using the diamonds dataset to analyze distributions of numeric variables
head(diamonds)
# carat cut color clarity depth table price x y z
# 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
# 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
# 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
# 4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
# 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
# 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
### Box-Plots
p = ggplot(diamonds, aes(x = cut, y = price, fill = cut)) +
geom_box-plot() +
theme_bw()
print(p)
En el gráfico, podemos ver las diferencias en la distribución de precios de los diamantes en diferentes cortes.
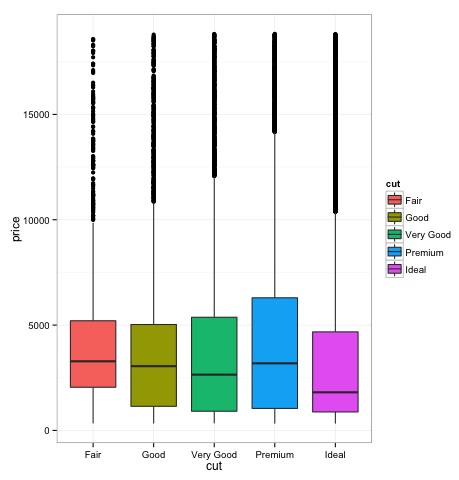
source('01_box_plots.R')
# We can plot histograms for each level of the cut factor variable using
facet_grid
p = ggplot(diamonds, aes(x = price, fill = cut)) +
geom_histogram() +
facet_grid(cut ~.) +
theme_bw()
p
# the previous plot doesn’t allow to visuallize correctly the data because of
the differences in scale
# we can turn this off using the scales argument of facet_grid
p = ggplot(diamonds, aes(x = price, fill = cut)) +
geom_histogram() +
facet_grid(cut ~., scales="free") +
theme_bw()
p
png('02_histogram_diamonds_cut.png')
print(p)
dev.off()
La salida del código anterior será la siguiente:
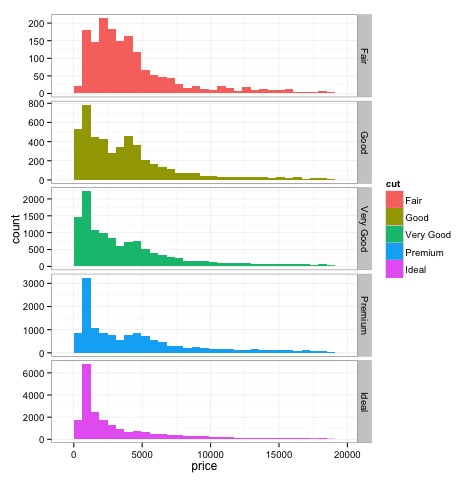
Los métodos de gráficos multivariados en el análisis de datos exploratorios tienen como objetivo encontrar relaciones entre diferentes variables. Por lo general, hay dos formas de hacer esto: construir una matriz de correlación de variables numéricas o simplemente construir los datos sin procesar como una matriz de diagrama de dispersión.
Para demostrar esto, usaremos un conjunto de datos de diamantes. Para seguir el código, abra el script. bda / part2 / charts / 03_multivariate_analysis.R…
library(ggplot2)
data(diamonds)
# Correlation matrix plots
keep_vars = c('carat', 'depth', 'price', 'table')
df = diamonds[, keep_vars]
# compute the correlation matrix
M_cor = cor(df)
# carat depth price table
# carat 1.00000000 0.02822431 0.9215913 0.1816175
# depth 0.02822431 1.00000000 -0.0106474 -0.2957785
# price 0.92159130 -0.01064740 1.0000000 0.1271339
# table 0.18161755 -0.29577852 0.1271339 1.0000000
# plots
heat-map(M_cor)
El código dará el siguiente resultado:
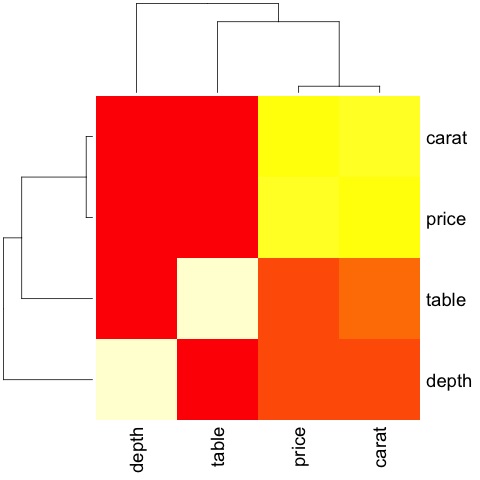
Este es un resumen, nos dice que existe una fuerte correlación entre precio y transporte, y no mucha entre las otras variables.
Una matriz de correlación puede ser útil cuando tenemos una gran cantidad de variables, en cuyo caso trazar datos brutos no es práctico. Como se mencionó, también se pueden mostrar datos sin procesar:
library(GGally) ggpairs(df)
El gráfico muestra que los resultados mostrados en el mapa de calor están confirmados, existe una correlación de 0.922 quilates entre precio y variables.
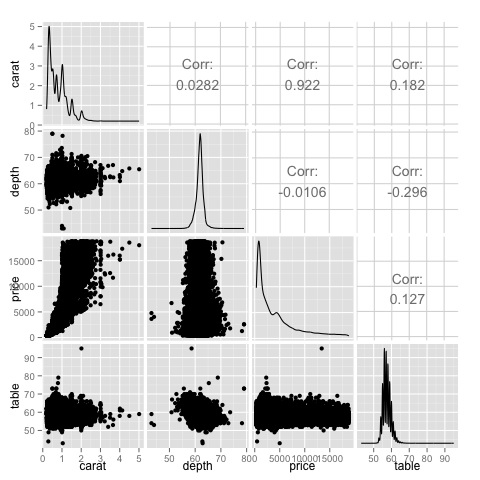
Esta relación se puede visualizar en una gráfica de dispersión de precio-quilate ubicada en el índice (3, 1) de la matriz de gráfica de dispersión.
🚫