
Big Data Analytics: análisis de series temporales
AREAtutorial » Big Data & Analitycs » Big Data Analytics: análisis de series temporales
Una serie de tiempo es una secuencia de observaciones de variables categóricas o numéricas indexadas por fecha o marca de tiempo. Un excelente ejemplo de datos de series de tiempo es la serie de tiempo de precios de acciones. En la siguiente tabla, podemos ver la estructura básica de datos de series de tiempo. En este caso, las observaciones se registran cada hora.
| Sello de tiempo | Promociones – Precio |
|---|---|
| 2015-10-11 09:00:00 | cien |
| 2015-10-11 10:00:00 | 110 |
| 2015-10-11 11:00:00 | 105 |
| 2015-10-11 12:00:00 | 90 |
| 2015-10-11 13:00:00 | 120 |
Por lo general, el primer paso en el análisis de series de tiempo es trazar una serie, generalmente utilizando un gráfico de líneas.
La aplicación más común del análisis de series de tiempo es predecir los valores futuros de un valor numérico utilizando una estructura de datos temporal. Esto significa que las observaciones disponibles se utilizan para predecir valores futuros.
El ordenamiento temporal de los datos implica que los métodos de regresión tradicionales son inútiles. Para construir un pronóstico confiable, necesitamos modelos que tengan en cuenta el orden temporal de los datos.
El modelo más utilizado para el análisis de series de tiempo se llama Media móvil autorregresiva (ARMA). El modelo consta de dos partes: autorregresión (AR) parte y media móvil (MA) parte. En este caso, el modelo se suele llamar ARMA (p, q) modelo donde PAG – el orden de la parte autorregresiva y q – el orden de la parte de media móvil.
EN AR (p) se lee como un modelo autorregresivo de orden p. Matemáticamente, esto se escribe como:
$$ X_t = c + sum_ {i = 1} ^ {P} phi_i X_ {t – i} + varepsilon_ {t} $$
donde {φ1,…, φp} son los parámetros a estimar, c es una constante y la variable aleatoria εt es ruido blanco. Necesita algunas restricciones en los valores de los parámetros, el modelo permaneció inmóvil.
Designacion MA (q) se refiere a un modelo de orden de media móvil q –
$$ X_t = mu + varepsilon_t + sum_ {i = 1} ^ {q} theta_i varepsilon_ {t – i} $$
donde θ1,…, θq son parámetros del modelo, μ es la expectativa matemática de Xt, y εt, εt – 1,… son los términos del error de ruido blanco.
EN ARMA (p, q) El modelo combina p términos de autorregresión y q términos de media móvil. Matemáticamente, el modelo se expresa mediante la siguiente fórmula:
$$ X_t = c + varepsilon_t + sum_ {i = 1} ^ {P} phi_iX_ {t – 1} + sum_ {i = 1} ^ {q} theta_i varepsilon_ {ti} $$
Vemos eso ARMA (p, q) el modelo es una combinación AR (p) y MA (q) modelos.
Para dar un poco de intuición al modelo, imagine que la parte AR de la ecuación busca estimar los parámetros de las observaciones de Xt – i para predecir el valor de la variable en Xt. Después de todo, es un promedio ponderado de valores pasados. La sección MA utiliza el mismo enfoque, pero con el error de las observaciones anteriores εt – i. Como resultado, el resultado del modelo es un promedio ponderado.
El siguiente fragmento de código demuestra cómo implementar ARMA (p, q) en R…
# install.packages("forecast")
library("forecast")
# Read the data
data = scan('fancy.dat')
ts_data <- ts(data, frequency = 12, start = c(1987,1))
ts_data
plot.ts(ts_data)
Trazar los datos suele ser el primer paso para averiguar si los datos tienen una estructura temporal. El gráfico muestra que al final de cada año hay fuertes oleadas.
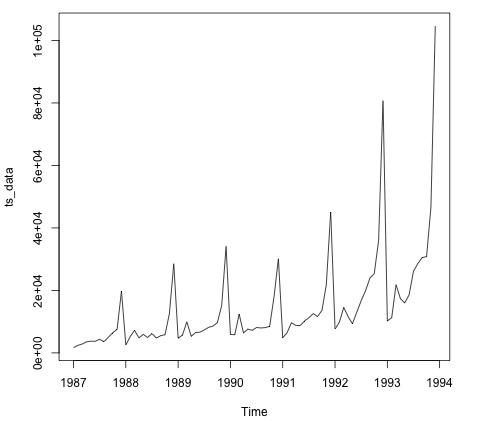
El siguiente código corresponde al modelo ARMA para datos. Ejecuta varias combinaciones de modelos y elige el que tiene menos errores.
# Fit the ARMA model fit = auto.arima(ts_data) summary(fit) # Series: ts_data # ARIMA(1,1,1)(0,1,1)[12] # Coefficients: # ar1 ma1 sma1 # 0.2401 -0.9013 0.7499 # s.e. 0.1427 0.0709 0.1790 # # sigma^2 estimated as 15464184: log likelihood = -693.69 # AIC = 1395.38 AICc = 1395.98 BIC = 1404.43 # Training set error measures: # ME RMSE MAE MPE MAPE MASE ACF1 # Training set 328.301 3615.374 2171.002 -2.481166 15.97302 0.4905797 -0.02521172
🚫