
Apache Pig – Instalación
AREAtutorial » Big Data & Analitycs » Apache Pig – Instalación
Este capítulo explica cómo descargar, instalar y configurar Pig apache en su sistema.
Antes de actualizar a Apache Pig, es importante que Hadoop y Java estén instalados en su sistema. Por lo tanto, antes de instalar Apache Pig, instale Hadoop y Java siguiendo los pasos que se dan en el siguiente enlace:
https://areatutorial.com/hadoop/hadoop_enviornment_setup.htm
En primer lugar, descargue la última versión de Apache Pig del siguiente sitio web: https://pig.apache.org/
Abra la página de inicio del sitio web de Apache Pig. Bajo la sección Noticias, haga clic en el enlace página de lanzamiento como se muestra en la siguiente imagen.

Cuando haga clic en el enlace especificado, será redirigido a Lanzamientos de Apache Pig página. En esta página debajo Descargar sección tendrá dos enlaces, a saber Pig 0.8 y más reciente y Pig 0.7 y anterior… Haga clic en el enlace Pig 0.8 y más reciente, luego será redirigido a la página con un conjunto de espejos.

Seleccione y haga clic en cualquiera de estos espejos como se muestra a continuación.
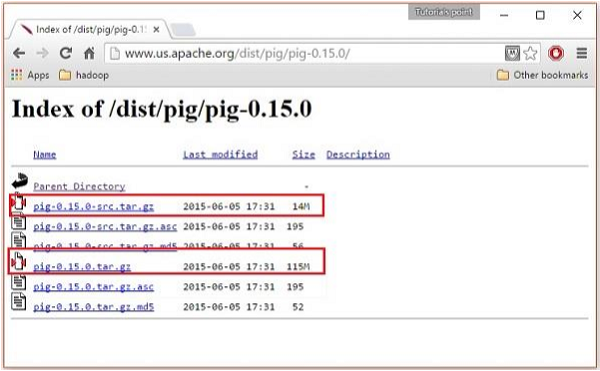
Estos espejos te llevarán a Liberaciones de cerdo página. Esta página contiene varias versiones de Apache Pig. Elija la última versión entre ellos.

En estas carpetas, tendrá el código fuente de Apache Pig y los binarios para varias distribuciones. Descargue los archivos tar binarios y fuente de Apache Pig 0.15, pig0.15.0-src.tar.gz y cerdo-0.15.0.tar.gz.
Después de descargar el software Apache Pig, instálelo en su entorno Linux siguiendo las instrucciones a continuación.
Cree un directorio llamado Pig en el mismo directorio que los directorios de instalación Hadoop, Java, y se ha instalado otro software. (En nuestro tutorial, creamos un directorio Pig en un usuario llamado Hadoop).
$ mkdir Pig
Extraiga los archivos tar descargados como se muestra a continuación.
$ cd Downloads/ $ tar zxvf pig-0.15.0-src.tar.gz $ tar zxvf pig-0.15.0.tar.gz
Mover contenido cerdo-0.15.0-src.tar.gz presentar en Pig directorio creado anteriormente como se muestra a continuación.
$ mv pig-0.15.0-src.tar.gz/* /home/Hadoop/Pig/
Después de instalar Apache Pig, necesitamos configurarlo. Para configurar, necesitamos editar dos archivos: bashrc y pig.properties…
en .bashrc archivo, establezca las siguientes variables:
CERDO una carpeta a la carpeta de instalación de Apache Pig,
PISTA variable de entorno a la carpeta bin y
PIG_CLASSPATH variable de entorno a la carpeta etc (config) de sus instalaciones de Hadoop (el directorio que contiene los archivos core-site.xml, hdfs-site.xml y mapred-site.xml).
export PIG_HOME = /home/Hadoop/Pig export PATH = $PATH:/home/Hadoop/pig/bin export PIG_CLASSPATH = $HADOOP_HOME/conf
en conf Carpeta de cerdo, tenemos un archivo llamado cerdo. propiedades… En el archivo pig.properties, puede establecer varios parámetros de la siguiente manera.
pig -h properties
Se admiten las siguientes propiedades:
Logging: verbose = true|false; default is false. This property is the same as -v
switch brief=true|false; default is false. This property is the same
as -b switch debug=OFF|ERROR|WARN|INFO|DEBUG; default is INFO.
This property is the same as -d switch aggregate.warning = true|false; default is true.
If true, prints count of warnings of each type rather than logging each warning.
Performance tuning: pig.cachedbag.memusage=<mem fraction>; default is 0.2 (20% of all memory).
Note that this memory is shared across all large bags used by the application.
pig.skewedjoin.reduce.memusagea=<mem fraction>; default is 0.3 (30% of all memory).
Specifies the fraction of heap available for the reducer to perform the join.
pig.exec.nocombiner = true|false; default is false.
Only disable combiner as a temporary workaround for problems.
opt.multiquery = true|false; multiquery is on by default.
Only disable multiquery as a temporary workaround for problems.
opt.fetch=true|false; fetch is on by default.
Scripts containing Filter, Foreach, Limit, Stream, and Union can be dumped without MR jobs.
pig.tmpfilecompression = true|false; compression is off by default.
Determines whether output of intermediate jobs is compressed.
pig.tmpfilecompression.codec = lzo|gzip; default is gzip.
Used in conjunction with pig.tmpfilecompression. Defines compression type.
pig.noSplitCombination = true|false. Split combination is on by default.
Determines if multiple small files are combined into a single map.
pig.exec.mapPartAgg = true|false. Default is false.
Determines if partial aggregation is done within map phase, before records are sent to combiner.
pig.exec.mapPartAgg.minReduction=<min aggregation factor>. Default is 10.
If the in-map partial aggregation does not reduce the output num records by this factor, it gets disabled.
Miscellaneous: exectype = mapreduce|tez|local; default is mapreduce. This property is the same as -x switch
pig.additional.jars.uris=<comma seperated list of jars>. Used in place of register command.
udf.import.list=<comma seperated list of imports>. Used to avoid package names in UDF.
stop.on.failure = true|false; default is false. Set to true to terminate on the first error.
pig.datetime.default.tz=<UTC time offset>. e.g. +08:00. Default is the default timezone of the host.
Determines the timezone used to handle datetime datatype and UDFs.
Additionally, any Hadoop property can be specified.
Verifique la instalación de Apache Pig ingresando el comando version. Si la instalación fue exitosa, obtendrá la versión de Apache Pig como se muestra a continuación.
$ pig –version Apache Pig version 0.15.0 (r1682971) compiled Jun 01 2015, 11:44:35
🚫